Monitorear jobs
Recomendación General
Asegúrese de reservar la cantidad de RAM y CPUs necesarios para la ejecución de su job. No reserve recursos que no necesita, ya que de hacerlo, perjudicará la ejecución de los demás usuarios del cluster.
A continuación se muestran algunos ejemplos de como medir el uso de CPU y RAM de su job a fin de que pueda refinar la reserva de recursos.
Jobs en ejecución
Si su job se encuentra en ejecución, es posible revisar su uso actual de recursos. No obstante, para conocer el uso máximo de CPU y memoria durante toda la ejecución, será necesario esperar a que el job finalice.
La forma más sencilla de monitorear el uso instantáneo de recursos consiste en crear un job interactivo superpuesto al job que se encuentra en ejecución, de modo que se acceda al mismo entorno de ejecución.
-
Para identificar el job que se desea monitorear, ejecute el comando:
El cual nos da como salida:squeue --meJOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 12345 debug bert-sar juan PD 0:00 1 n001Este comando muestra la lista de jobs que se encuentran actualmente en ejecución bajo su usuario. A partir de esta información, identifique el JOBID correspondiente al job que desea supervisar. En el ejemplo anterior, el identificador del job es 12345.
-
Utilizando el identificador del job, se creará un job interactivo superpuesto al job en ejecución con:
srun --pty --jobid=12345 --overlap --pty /usr/bin/bash -
Una vez dentro del nodo de cómputo, ejecutaremos
ps,htop,nvidia-smi, onvtop.-
psle brindará la información instantánea del uso de recursos cada vez que ejecute el comando.[usuario@n001 ~] ps -u$USER -o %cpu,rss,args %CPU RSS COMMAND 0.0 2376 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.py 0.0 2380 python triangle.pyEl reporte de memoria de
psse muestra en KB, podemos notar que los procesos listados consumen alrededor de 2000 KB de RAM y que el uso de los CPUs es casi nulo. -
htopse ejecuta de manera interactiva y muestra las estadísticas de uso en vivo. Puede presionar la teclau, ingresar su nombre de usuario y luegoenterpara filtrar solo sus procesos. La información del uso de memoria, se encuentra en la columna RES. Para solicitar ayuda puede presionar?y si desea salirq.
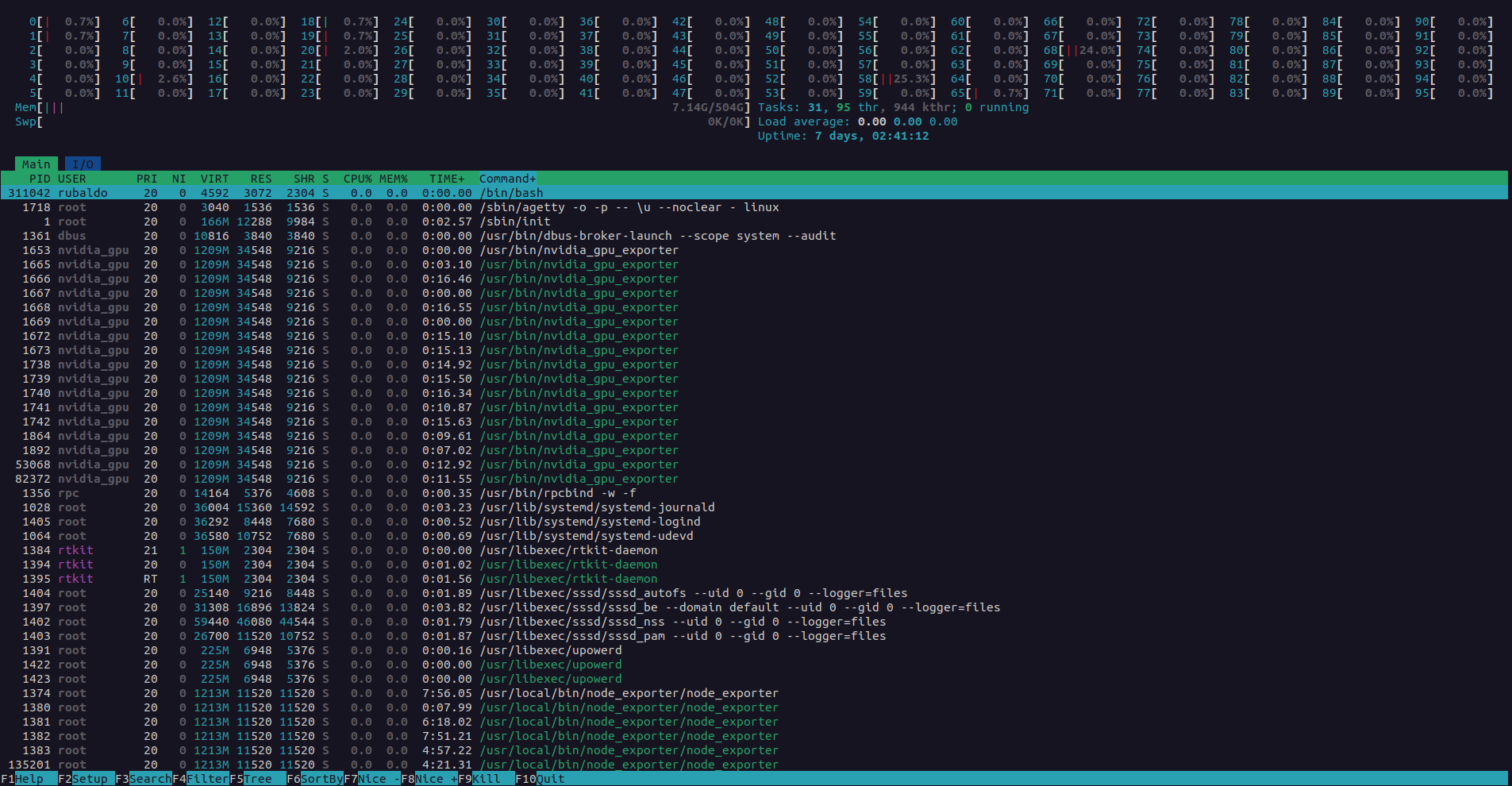
-
nvidia-smi: muestra el estado de las tarjetas GPU y los jobs que se encuentran haciendo uso de ellas, incluyendo información sobre utilización, memoria ocupada y procesos activos.[usuario@n001 ~]$ nvidia-smi Sat Dec 01 18:02:24 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.51.03 Driver Version: 575.51.03 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A30 Off | 00000000:2A:00.0 Off | 0 | | N/A 37C P0 94W / 165W | 23167MiB / 24576MiB | 57% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA A30 Off | 00000000:3D:00.0 Off | 0 | | N/A 36C P0 67W / 165W | 23167MiB / 24576MiB | 43% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 312341 C /workspace/hpl-linux-x86_64/xhpl 23158MiB | | 1 N/A N/A 312323 C /workspace/hpl-linux-x86_64/xhpl 23158MiB | +-----------------------------------------------------------------------------------------+ -
nvtop: muestra de forma interactiva (similar ahtop) los jobs y procesos que están utilizando las tarjetas GPU, permitiendo monitorear en tiempo real su uso de cómputo y memoria.
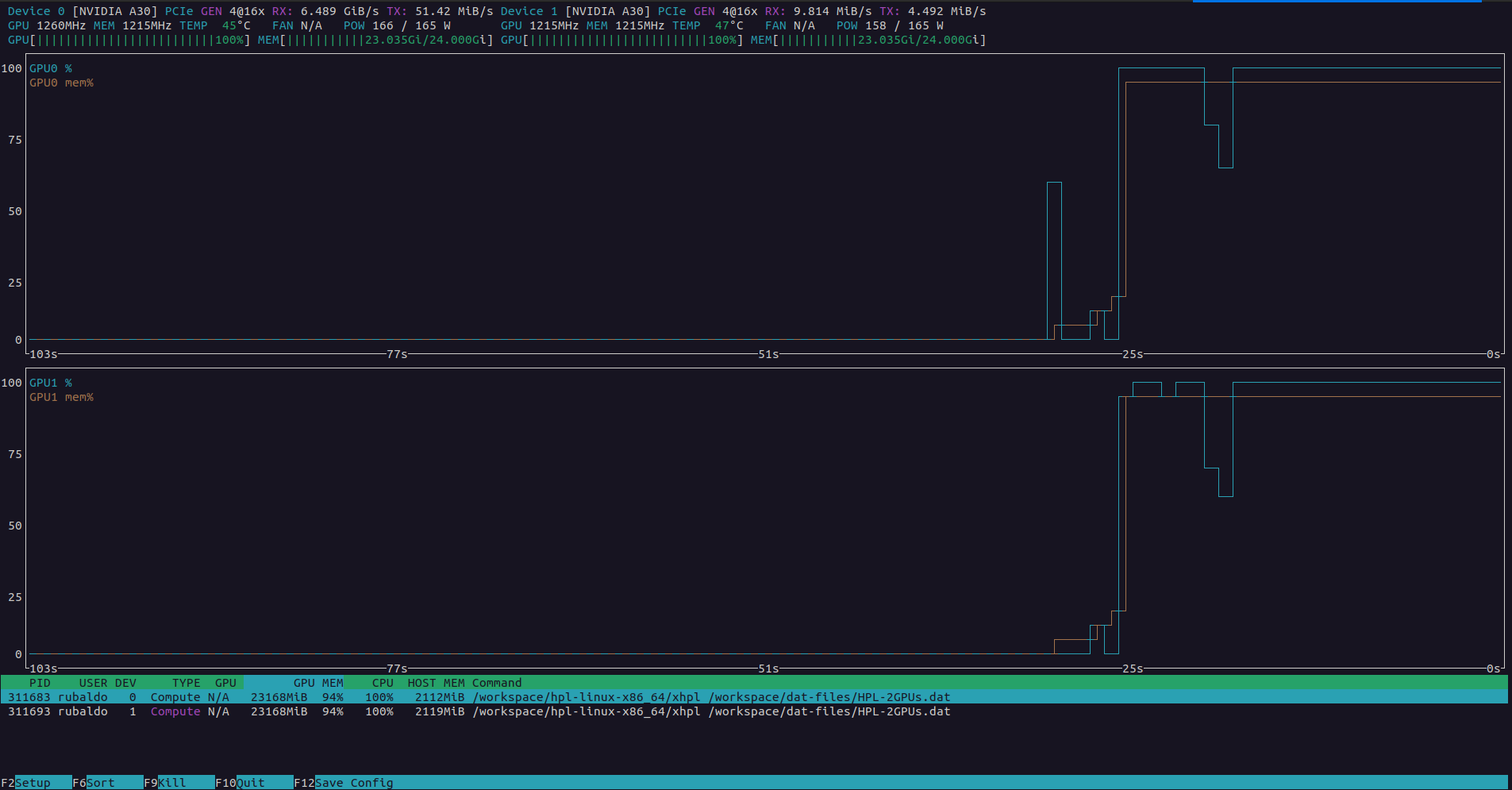
-
Jobs finalizados
Slurm guarda las estadísticas de cada job, incluído cuanta memoria y CPU fue utilizada.
sacct
También se puede usar sacct para obtener la información del job. Lamentablemente, el output por defecto de sacct no es del todo entendible, por ello se recomienda procesar la salida de la siguiente manera.
[usuario@raimondi ~]$ export SACCT_FORMAT="JobID%20,JobName,User,Partition,NodeList,Elapsed,State,ExitCode,MaxRSS,AllocTRES%32"
[usuario@raimondi ~]$ sacct -j 12345
JobID JobName User Partition NodeList Elapsed State ExitCode MaxRSS AllocTRES
---------- ---------- --------- ---------- --------------- ---------- ---------- -------- ---------- --------------------------------
12345 simple_ex+ alan.tur+ debug n001 00:00:11 COMPLETED 0:0 billing=2,cpu=2,mem=200M,node=1
12345.batch batch n001 00:00:11 COMPLETED 0:0 cpu=2,mem=200M,node=1